
Choosing not to be an AI SOC... and going Headless instead

There are now somewhere north of 100 vendors advertising AI-powered SOC capabilities. Agentic SOC, autonomous analyst, AI triage. The LinkedIn post mapping that grid has become a Rorschach test for security people: some see progress, some see a bubble, most see their inbox getting worse.
The honest version of what I’ve tested: a well-designed interface and a decent LLM prompt on top of whatever detection platform you already had. The model is just what Anthrophic’s is. The prompting may be clever. The data underneath is still what it was.
An agent runs a query. It waits three minutes for [insert SIEM x data repo here] to spin up. It gets 30 days of data back instead of the 90 it needed. It writes you a beautifully formatted incident summary describing a very much incomplete picture.
Just a few days ago, a security team was investigating a potential TanStack supply chain compromise across high-profile NPM and PyPI projects. They needed logs. They had 180 days of retention. Most of it was sitting in Elastic's frozen tier, which meant every query was a waiting exercise. The older data lived in S3, taking several hours to run. The logs existed. The timeline they needed was in there somewhere. Putting it together was a real mess.
A better interface on top of slow data is still slow data. Whether the AI SOC conversation is moving in the right direction is a fair debate. Whether it is moving fast enough to keep up with how teams actually need to investigate is a different question.
The Traditional SOC vs. the Agentic SOC
An agentic SOC is where AI agents handle L1 triage end-to-end. Done well, this is different from an AI SOC, which usually means AI features bolted onto an unchanged analyst workflow.
The traditional SOC has a familiar shape. Alerts come in. An L1 analyst triages them. Interesting ones go to L2. The few that matter reach a senior engineer or the CISO. At every handoff, someone opens a tool, runs a search, reads logs, writes a summary, and passes it along.
The agentic SOC does not eliminate that chain. It shifts who does the first several steps. An agent pulls context, correlates events, writes up what it found, and routes with a recommendation. Humans enter at the point where judgment actually matters.
The Headless SOC
A headless SOC is one where the detection and investigation loop runs without a human-facing security interface in the middle. The term is borrowed from web architecture, where a headless system serves content through APIs instead of its own frontend.
The interface for a headless SOC is Slack, Notion, or a Jira ticket with a pre-filled timeline. Wherever the team already reads. The SIEM tab stays closed.
Headless does not mean no UI exists. Detection engineers still have dashboards. Analysts still have query interfaces when they want them. It means the investigative loop runs without requiring anyone to touch those interfaces. You can run it from Claude Code. From a terminal via CLI. From a Slack thread. The security tooling becomes infrastructure rather than workspace.
The friction in traditional SOC work is not usually the analysis. Ask any detection engineer where time actually goes during an investigation and the answer is navigation: opening the right tool, finding the right query syntax, correlating across four different UIs, reformatting results into a ticket that someone else can read. The analysis, when you finally get to it, is the most valuable part of this equation but you have to do to ensure the right ingredients are well prepped in the data layer in order to even start cooking.
Notion’s Implementation
Notion's security team built an agent they call Scruff. They do not log into Wiz, CrowdStrike, or Scanner in a browser tab.
When an alert fires, Scruff queries Scanner's MCP for the relevant event history. It pulls the associated CrowdStrike and Wiz context via their APIs. It correlates the findings, builds a timeline, scores the risk, and writes up an investigation summary with citations in the format the team reads. The result lands in Notion or Slack before anyone opens a laptop.
At 2am, a high-severity alert comes in. By the time the on-call engineer's PagerDuty page goes out, the case is 90% complete. The engineer reads a structured summary. They make a judgment call. They close the ticket or escalate. Total time inside any security tool UI: close to zero.
See for yourself: Meet Scruff, Notion's New Security AI Teammate.
The headless architecture is fundamentally broken down into three layers.

Top: where humans and agents meet; Slack, Notion, Jira, Claude.
Middle: the agent layer, either yours or a vendor's.
Bottom: the headless tools; CrowdStrike, Wiz, Okta, and Scanner for everything in log data.
The tools do the work. The humans read the output. The security tooling becomes invisible.
Our bet on this architecture is a single consistent surface: the same API for a human or an agent. Whatever you can do in the Scanner console, an agent can do through MCP. No visibility limits. No speed penalty. First-class agentic access on the same surface as the human one.
What makes this work is not the agent. It is what the agent can see.
A 30-day retention window and a three-minute query produce a slow investigation with better formatting. Agents derive their usefulness from iteration speed: query, refine, pivot, conclude. That loop collapses when each step carries real latency.
One query at three minutes is inconvenient. Five queries at three minutes is an investigation that takes longer than a human working through it manually. And that is before you factor in the agent that needs to reach data from three months ago, or a field the SIEM schema has never seen.
Federated search attacks a real problem: ETL lag, data movement cost, wanting to query in place. But federated queries are stateless. They hit a live API and return a snapshot of now. They have no indexed history, no cross-source context, no ability to reconstruct what happened six weeks ago. An agent building a timeline on federated results is building on whatever retention window the source system's API happens to expose. Scanner gives agents months or years of indexed history. The difference is the whole game for investigation work.

Why We Are Choosing to Go All In on Headless
Most security teams are not starting from scratch. They have existing tooling. They have retention they have already paid for. In most cases, that data is already in S3.
The teams that have built working agentic investigation loops tend to describe the same inflection point: once the agent is querying fast data, you stop opening the search interface for routine alerts. The output goes to Slack. The SIEM tab stays closed. Somewhere between MCP and a fast data layer, the console became optional.
There is also a more practical reason teams are choosing to build rather than buy an AI SOC: no vendor knows your environment the way you do. The detection logic that matters for a fintech running under PCI-DSS looks nothing like what matters for a healthcare org with HIPAA obligations and a shared-responsibility cloud model. The SRE escalation thresholds your team has negotiated over two years of incidents are not in any vendor's playbook. The blast radius of a given alert in your environment, the integrations that are actually instrumented versus the ones that are technically deployed, which third-party identity providers are legacy and which are authoritative; that institutional knowledge lives with your team. An AI SOC vendor who has not spent time as a practitioner in your specific stack cannot encode it for you, not out-of-the-box anyway.
Scanner's version of an agentic SOC is the headless one: a searchable data layer with no restrictions on what function of the SOC can run against it. Detection engineering, threat hunting, incident response. But also the functions that traditional SIEMs were never designed for: SRE triage, fraud operations, GRC compliance, and anything else your organization routes through S3. One data layer. The interface on top is what becomes flexible.
That flexibility is already shipping. Several /skills already ask whether you want results as HTML — a purpose-built interface generated for that output, not a dashboard you maintain. Detection rules migrated from older SIEMs into ScannerQL. Case summaries formatted for Notion. The head is becoming plastic from inside the product.
The roadmap goes further. Scanner will run agents within Scanner. The data layer and the agent layer will share the same surface. When that is ready, the distinction between building on Scanner and using Scanner as your security operations center may start to blur. For now, the teams building their own agents on Scanner's data layer are getting there first, and then getting it tailored to their own environment rather than a vendor's default playbook.
The precondition for all of it is the same: fast, complete data. That is worth checking before evaluating which agent or interface sits on top of it.
Learn more about what you can do headless via MCP in our docs.
Before evaluating any security data architectures, run some of the following scans:
Especially if the AI SOC inquestion is claiming to ingest data & execute detection logic.
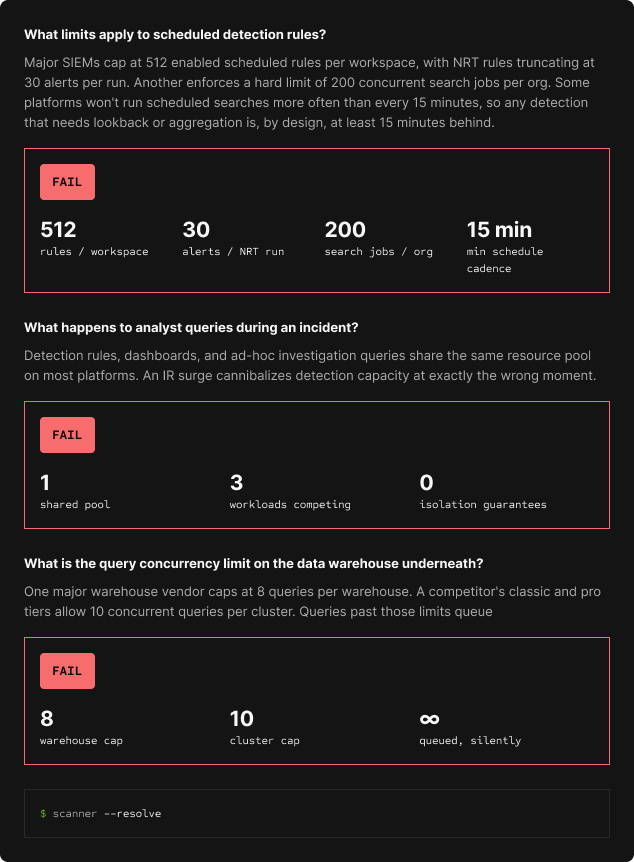
These are designed behaviors, visible in the documentation of those platforms.
The agent you are evaluating inherits every one of those constraints.
Most of the evaluation criteria applied to AI SOC tools right now are interface criteria: which model, which workflow tool, how clean is the case output. The question that determines whether any of it works in practice is what happens when the agent needs data the platform cannot deliver fast enough, or at all.
The MCP surface is only as useful as what the data layer returns. Schema awareness, field context, the ability to iterate on a query without rewriting it from scratch: these determine whether an agent can investigate or just retrieve. Fast retrieval with years of retention and no lookback penalty means the agent does the work. Slow retrieval with a 30-day window means the agent is thinking really hard, caramelizing onions, or probably frolicking off somewhere while the IR clock runs.
